Linear Regression 의 관심
지난 시간에 알아봤던 Linear Regression 의 Cost 함수는 다음과 같다.

우리의 관심은 , 우리가 조작 가능한 W 값(x 의 기울기)과 b 값(y 절편)을 조정하여 Cost 함수 값이 가장 적게 나오는 모델을 결정하는 것이다.
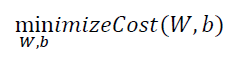
Gradient Descent Algorithm
우선 지난 번 예시로 살펴보았던 데이터를 보자
| X | Y |
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
또한 가설 함수 H(x) = Wx 라고 하면, (b 값을 0이라고 하자) 다음과 같은 Cost 함수가 표현된다.

이 함수(Cost 함수)의 모형을 그려보면 다음과 같다.

W 값에 따라 Cost 함수값이 달라지는 것을 확인할 수 있다. W가 0일 때는 Cost 값이 0.4667이고, 1로 갈수록 점점 줄어들어 0이 되며, 그 이후부터는 점점 다시 증가하는 것을 확인할 수 있다.
즉, 이 데이터에서 Cost 함수를 가장 줄일 수 있는 W 값은 1이라는 것을 확인할 수 있다.
이처럼 Cost 가 최소화되는 지점을 기계적으로 찾을 때 적용하는 Algorithm이 바로 Gradient Descent Algorithm이다. 만약, 특정한 점에서 기울기가 음수이거나, 양수라면 기울기가 0이 되는 변곡점으로 찾아가는 알고리즘이다.


Gradient Descent Algorithm은 Cost Function을 최소화하는데 많이 사용되며, 최소화 문제에 많이 사용된다.
기본적인 작동 원리는 다음과 같다.
1. 임의의 시작점에서 출발한다.
2. Cost 함수가 줄어들 수 있게, W 값과 b값을 조금 바꾼다.
3. 해당 지점에서의 경사도를 계산하고, cost 함수가 줄어드는 경사도 방향을 선택한다.
4. Local Minimum에 도달할 때까지 2,3 번 과정을 반복한다.
위의 그림과 같은 2차 함수 Cost 함수에서는 Gradient Algorithm을 적용하면 항상 Local Minimum이 Global Minimum이 되게 된다. 밑줄친 경사도 계산은 미분을 통해 진행되게 된다.

결국 최적화된 W 값은 다음과 같이 구해지게 된다.

이렇게 최적화된 W 값을 계속 갱신하다보면, Cost 함수 값이 Minimum이 되는 W 값을 구할 수 있게 된다.
Convex Function
위에서 Local Minimum이라는 표현을 사용했다. 어떤 함수에서는 Local Minimum과 Global Minimum이 다른 경우도 존재하기 때문이다.

이러한 Cost function 모형이 존재한다고 할 때, 시작점에 따라 Gradient 값이 0이 되는 지점이 달라, 항상 Cost Fuction이 최소가 되는 점을 구할 수 없는 문제가 생기게 된다. 그러므로, Gradient Algorithm을 적용하기 위해서는 우리의 Cost Function의 모형이 Convex Function (볼록함수)인지를 확인해보아야 한다.
Convex Function에서는 어느 점에서 시작하던지 도착하는 점이 Cost Function이 최소가 되는 지점에 도착하고, Gradient Descent Algorithm이 항상 답을 찾을 수 있다.
'DataScience > Machine Learning Basic' 카테고리의 다른 글
| Multivariable linear regression (0) | 2022.02.21 |
|---|---|
| Tensorflow Linear Regression Implementation (1) | 2022.01.26 |
| Linear Regression (0) | 2022.01.25 |
| Tensorflow 기본 Operation (0) | 2022.01.21 |
| Tensorflow in Pycharm 그리고 Google Colab (0) | 2022.01.21 |



